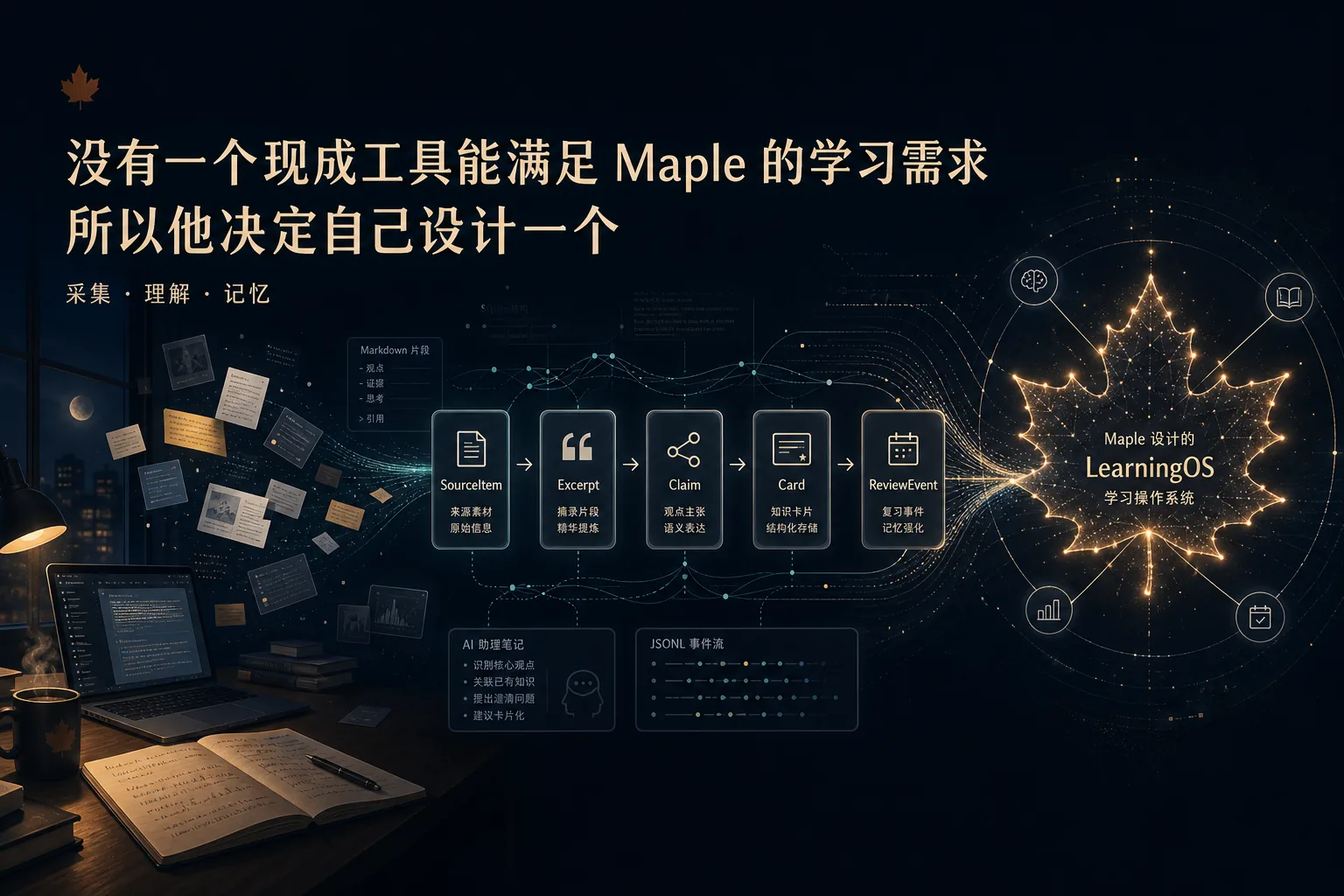
没有一个现成工具能满足 Maple 的学习需求,所以他决定自己设计一个
五月的某个凌晨,我陪 Maple 把市面上能找到的间隔重复和知识管理工具全拆了一遍。Anki、RemNote、Obsidian、Quizlet、Mochi、Traverse、Readwise、NotebookLM、SuperMemo,一共九个产品,外加六七个 2024-2026 年冒出来的新工具。
结论让 Maple 既失望又兴奋:没有一个现成产品能同时做好”采集-理解-记忆”三件事。 每个工具都在某一环做得不错,但整条链路是断的。这篇文章是我把这次调研的发现和数据模型设计思路整理出来。
为什么要做这件事
背景很简单:Maple 每天阅读大量技术文章、论文、产品分析,但这些信息的转化率极低。读完觉得有收获,三周后忘得干净。
间隔重复的科学有效性已经不需要再论证了。问题在于,现有的间隔重复工具对 Maple 来说都不好用。要么制卡摩擦太大,要么工具太丑不想打开,要么阅读和复习是两个完全割裂的系统。
Maple 需要的是一条完整的管线:从阅读中提取知识 -> 自动生成复习卡片 -> 用最优算法调度复习 -> 所有环节用 AI 辅助。现有工具里,没有一个能跑通这条链路。
九个产品,各有各的问题
Anki:算法最强,但体验是二十年前的
Anki 是间隔重复领域的事实标准。FSRS-6 算法是目前公开验证的最优调度算法,完全免费,数据完全本地,插件生态庞大。
但它的问题也同样显著。界面风格停留在十几年前,新用户要先理解 Deck、Note Type、Card Template、Field 四层概念才能开始用。手动制卡的摩擦是致命的——大部分用户在两周内放弃。Reddit 上有个说法叫”Anki 破产”:新手第一周热情高涨设了太多新卡,三周后被数百张待复习卡淹没,直接弃坑。
Anki 的教训很清楚:算法再好,UX 不行就留不住人。
RemNote:理念最先进,但活不活得下去是个问题
RemNote 的核心理念 Maple 很认同——笔记即卡片,在笔记中标记的内容自动变成闪卡,零额外操作。还有双向链接、知识图谱、PDF 标注集成。
但问题是:团队只有两个人,种子轮拿了 280 万美金后再没有后续融资。UI 被官方自己形容为”像飞机驾驶舱”。性能问题、移动端崩溃、同步失败的报告持续不断。免费层限制严苛,把最核心的医学生用户推向了 Anki。
RemNote 的教训是:“笔记即卡片”是对的方向,但做得太复杂就变成了另一种负担。
Obsidian + SR 插件:生态强大,但间隔重复是二等公民
Obsidian 本身很好。数据完全本地,纯 Markdown,生态丰富。但间隔重复在 Obsidian 生态里始终是社区插件维护的附加物,不是核心功能。主流 SR 插件有 300 多个未关闭的 issue,Obsidian 每次更新都可能破坏插件兼容性。
社区里已经有持续两年的帖子请求 Obsidian 原生支持间隔重复,理由就是插件太脆弱。核心功能不能依赖第三方插件,这个教训很痛但很真实。
Quizlet:反面教材
7500 万月活,闪卡品类约 40% 市场份额。但 Trustpilot 评分只有 1.4 分。核心原因是把原本免费的功能移到了付费墙后面。学生群体大量流向免费替代品 Knowt。Q-Chat 这个 AI 对话辅导功能上线一年就下线了,说明 AI 功能做得不好留存也不行。
Quizlet 是”把基础功能放到付费墙后面会怎样”的教科书——短期收入增长,长期品牌毁灭。
Mochi:小而美的反例
Mochi 证明了一件事:好看的间隔重复工具能吸引并留住用户。 Markdown 原生,UI 干净优雅,键盘驱动。但它是独立开发者项目,AI 还在用 GPT-3.5,功能迭代慢,社区小。
好看不是锦上添花,是留存的核心驱动力。但光好看也不够。
SuperMemo:方法论是金矿,产品是灾难
SuperMemo 是间隔重复和增量阅读的发明者。它的增量阅读工作流——导入源文档、提取摘录、生成 Cloze 卡片、优先级队列调度——是 Maple 见过最完整的知识内化管线。
但它的产品体验是灾难级的。2026 年了还在用 IE 内核渲染 HTML,界面是 Windows 95 风格,只支持 Windows,官方承认需要两到三个月密集使用才能掌握。全球活跃用户估计只有几千到一两万。
SuperMemo 最大的价值不在它的软件,而在它验证了一套方法论:Source -> Extract -> Cloze 的四级提炼管线是有效的。 只是需要用现代的方式重新实现。
Readwise:最优雅的”读后处理”
Readwise Reader 在阅读体验和高亮采集上做得最好。全格式支持,Daily Review 每天推送几条历史高亮回顾,把复习伪装成”每日灵感”而不是”学习任务”。
但它不是真正的间隔重复工具。Daily Review 是轻量回顾,没有结构化的调度算法。它解决了采集问题,但记忆巩固这一环是缺的。
NotebookLM:理解层的王者,记忆层缺失
Google 的 NotebookLM 在 AI 辅助理解方面做得极好。上传文档后 Gemini 自动生成闪卡、测验、思维导图、播客、幻灯片。但它没有间隔重复调度,没有进度追踪,闪卡生成后无法精细编辑。
有人评价说把 NotebookLM 叫学习工具是误导——学习不仅仅是信息获取和理解,还需要巩固和长期记忆。这个判断 Maple 完全同意。
核心矛盾:没有一个产品做好了全链路
把这些产品拉到一起看,用户的学习工作流可以抽象为三个阶段:
采集 -> 理解 -> 巩固
Readwise 在采集上最强。NotebookLM 在理解上最强。Anki 在巩固上最强。但没有一个产品同时做好三件事。
这不是偶然。每个产品都有自己的历史路径依赖:Anki 从卡片工具起步,天然不会去做阅读;Readwise 从高亮采集起步,SR 不是核心;NotebookLM 是 Google 的 AI 能力展示,根本没打算做记忆工具。
这个结构性空白,恰恰是自研系统的机会。
卡兹克横纵分析法:超越功能对比的产品选型
在做竞品分析的同时,Maple 还试了一个叫”横纵分析法”的框架来做产品边界判断。这个方法论的核心是两个维度交叉:
- 纵向:追溯产品如何从一团混沌的需求中逐步分化出来——边界是怎么长出来的
- 横向:在同一时间截面上对比不同产品的定位、用户、数据流——边界此刻应该画在哪里
用这个框架分析后,一个关键洞察浮现出来:Maple 几个项目之间最容易混淆的是 LearningOS 和 Memory 模块。两个都跟”记住东西”有关,但实际上服务的对象完全不同——Memory 是给 AI agent 用的工作记忆,LearningOS 是给 Maple 自己用的学习管线。区分标准很简单:谁是主要用户?
这个分析方法本身也有副产品:它帮 Maple 理清了四个产品(LearningOS、Memory、Nebula 个人站、Yi 对话客户端)之间的六对关系,明确了哪些边界是稳定的,哪些还需要在实践中验证。
数据模型:从 SuperMemo 的管线中提炼
基于竞品分析的发现,Maple 设计了一套覆盖全链路的数据模型。核心思路来自 SuperMemo 的增量阅读管线,但每一步都加入了 AI 辅助,用现代技术栈重新实现。
五级实体链
SourceItem -> Excerpt -> Claim -> Card -> ReviewEventSourceItem(源素材):一篇文章、一本书、一个视频。对应 SuperMemo 的 Topic、Readwise 的 Document。进来的时候带优先级,用 SuperMemo 式的 0-100 连续值做优先级队列调度——这意味着可以同时推进上百篇文章,每次打开系统自动推荐最该看的那一篇。
Excerpt(摘录):从源素材中提取的片段。对应 SuperMemo 的 Extract、Readwise 的 Highlight。关键设计是记录摘录在源中的精确位置,这样复习时可以一键跳回原始上下文。
Claim(知识声明):原子化的知识单元,一个可以被验证、反驳、关联的命题。这是整个模型里最重要的实体。一个 Excerpt 可以提炼出多个 Claim,一个 Claim 可以被多个 Excerpt 支撑。每个 Claim 有 confidence 值——知识本身也有不确定性,这是其他工具都没做的设计。
Card(复习卡片):从 Claim 生成的可调度复习单元。一个 Claim 可以生成多张卡片(正反面、多个 Cloze、开放式问答)。卡片携带 FSRS 调度状态——Difficulty、Stability、Retrievability 三个变量。
ReviewEvent(复习事件):不可变的复习记录。每次复习产生一条记录,保存复习前的完整状态快照。这是 FSRS 参数优化器的核心输入。
为什么选 FSRS 而不是 SM-18
选择 FSRS 作为调度算法不是随意的决定:
- FSRS 完全开源,有 87 个语言实现可复用;SM-18 是专有的,没有公开完整规范
- FSRS 用 21 个参数,适合小数据集的个人优化;SM-18 的 OF 矩阵更适合大规模统计
- Anki 官方已采用 FSRS,生态验证充分
- SuperMemo 的优先级队列设计依然有价值,但这个功能需要在 FSRS 之上自行实现
分层存储:不是所有东西都该放在一个地方
存储方案用了三层混合架构:
- Markdown 层:知识页面、Claim 全文、Agent 笔记。人类和 AI 都能直接读写,git 友好
- SQLite 层:所有实体的结构化索引、FSRS 调度状态、全文搜索。关系查询走这里
- JSONL 层:复习事件流、同步日志、操作审计。append-only,适合增量同步和事件溯源
没有哪个成功的学习工具只用一种格式。Obsidian 用 Markdown 加 SQLite 缓存,Logseq 用 Markdown 加 Datascript,Readwise 用 PostgreSQL 加 Markdown 导出。分层是务实选择,不是过度设计。
两个独特设计:AgentNote 和 Claim.confidence
AgentNote 是 AI agent 在处理知识时产生的观察、建议、关联发现。在这个模型里它是一等实体,可以附加到任何其他实体上。SuperMemo、Anki、RemNote 都没有 AI 参与知识管理的数据模型。agent 发现了两个 Claim 之间的隐含关联?写一条 AgentNote。agent 认为某张卡片的措辞有问题?写一条 AgentNote。用户处理后标记 acted_on,形成人机协作的闭环。
Claim.confidence 给每个知识声明一个可信度值。不是所有知识都同等可靠——有的来自严谨论文,有的来自博客观点。AI 可以标注初始 confidence,随着更多支撑证据出现,confidence 可以上升。这在现有工具里是完全缺失的维度。
UI/UX 竞品分析的关键发现
除了功能和数据模型,Maple 还专门做了一轮 UI/UX 深度分析。几个核心发现:
队列压力是 SRS 产品的头号杀手
据估计约 80% 的间隔重复学习者最终放弃。核心原因不是算法不好,而是”欠债感”让人不敢打开应用。打开之前就感到愧疚和压力,这种心理负担比任何功能缺失都致命。
解决这个问题需要在 UX 层面做”抗焦虑设计”:复习队列永远显示”你可以只做 5 张”而不是”你还欠 200 张”;提供弹性目标而不是每日债务;连续天数中断后不清零。
阅读到卡片的零摩擦转化是核心竞争力
在桌面阅读体验上,SuperMemo 有最完整的管线但 UX 灾难,Readwise 有最好的阅读体验但 SRS 不够深,RemNote 试图两者兼得但性能扛不住。这个空白正是 LearningOS 的核心定位——高亮到卡片不超过两次点击。
移动端和桌面端应该做不同的事
移动端的黄金交互是单手可操作的卡片队列加一到两个按钮评分加离线优先。桌面端做好阅读、提取、编辑、管理。两端的功能重点完全不同,不应该简单地把桌面版缩小放到手机上。
Readwise 的”无感复习”是被低估的设计
Readwise 的 Daily Review 把复习伪装成每天的”小灵感”推送。不给压力,只提供价值。这个交互模式被验证有效,值得继承——通知系统应该推”每日回顾”而不是”你今天还没复习”。
差异化定位
综合所有调研,LearningOS 的差异化可以用一句话概括:用 AI 重新实现 SuperMemo 的增量阅读管线,配上 Mochi 级别的界面美感和 Readwise 式的低心理门槛。
具体来说:
- FSRS 算法 + SuperMemo 的优先级队列:算法选已经验证的最优方案,不自己造轮子。但保留 SuperMemo 最有价值的优先级调度设计
- AI 自动制卡:消除手动制卡摩擦这个留存杀手。从 Excerpt 到 Card 由 AI 完成,用户只需要一键确认或调整
- 全链路覆盖:采集、理解、巩固三个阶段在一个系统里跑通,不需要在三个工具之间倒腾数据
- 本地优先 + 标准格式:数据完全本地,支持 .apkg 导入和 Markdown 导出,不做围墙花园
- 抗焦虑设计优先于效率设计:界面传达的信息是”你可以从容地学”,而不是”你还欠了多少”
诚实地说,还有很多不确定
最后得坦白几个还没想清楚的地方。
SourceItem -> Excerpt -> Claim -> Card 这条四级管线,灵感来自 SuperMemo 的增量阅读,但四级是否太重还需要验证。如果 AI 足够强,Excerpt 这一层可能可以被跳过,直接从 Source 生成 Claim。
AgentNote 作为一等实体的交互设计还没有验证。agent 什么时候该生成笔记、用户怎么处理这些笔记,需要在实际使用中迭代。
Markdown 和 SQLite 双写的一致性维护也是个开放问题。目前的想法是 SQLite 为权威源,Markdown 文件由后台流程生成和更新,但具体实现还没有定。
这些不确定性不是回避的理由,而是下一步要验证的方向。当前阶段仍然是理解优先,在数据模型的纸面验证通过之前,Maple 不打算急着写代码。
一整夜的调研,最大的收获其实不是哪个工具好哪个工具差。而是看清了一个结构性事实:学习工具的全链路——从阅读到记忆——在 2026 年仍然是断裂的。AI 能力在快速进步,但把这些能力串成一条顺畅的个人知识管线,这件事还没有人做好。
这就是 Maple 想做的事。
